About
We present the _o_ops_!_ dataset for studying unintentional human action. The dataset consists of 20,723 videos from YouTube fail compilation videos, adding up to over 50 hours of data. These clips, filmed by amateur videographers in the real world, are diverse in action, environment, and intention. The dataset covers many causes of failure and unintentional action, including physical and social errors, errors in planning and execution, limited agent skill, knowledge, or perceptual ability, and environmental factors.
Statistics
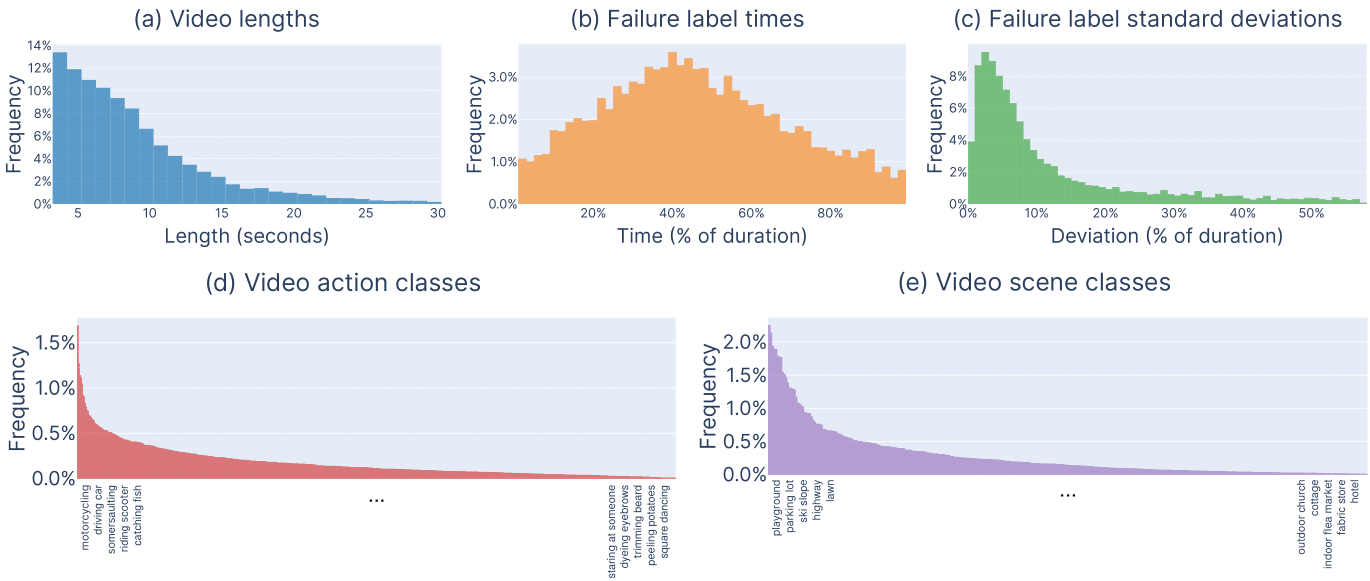
We summarize our dataset with the (a) distribution of clip lengths, (b) the distribution of temporal locations where failure starts, and (c) the standard deviation between human annotators. The median and mean clip lengths are 7.6 and 9.4 seconds respectively. Median standard deviation of the labels given across three workers is 6.6% of the video duration, about half a second, suggesting high agreement. We also show the distribution of (d) action categories and (e) scene categories, which naturally has a long tail. For legibility, we only display the top and bottom 5 most common classes for each.
Citation
@article{epstein2019oops,
title={Oops! Predicting Unintentional Action in Video},
author={Epstein, Dave and Chen, Boyuan and Vondrick, Carl.},
journal={arXiv preprint arXiv:1911.11206},
year={2019}
}
Team
 Dave Epstein
Dave Epstein
 Boyuan Chen
Boyuan Chen
 Carl Vondrick
Carl Vondrick